Содержание
7 бесплатных программ для мониторинга сети и серверов
Практикум /
Мантра мира недвижимости — Местоположение, Местоположение, Местоположение. Для мира системного администрирования этот священный текст должен звучать так: Видимость, Видимость и еще раз Видимость. Если каждую секунду на протяжении всего дня вы досконально не знаете, что делают ваша сеть и сервера, вы похожи на пилота, который летит вслепую. Вас неминуемо ждет катастрофа. К счастью для вас, на рынке сейчас доступно много хороших программ, как коммерческих, так и с открытым исходным кодом, способных наладить ваш сетевой мониторинг.
Поскольку хорошее и бесплатное всегда заманчивее хорошего и дорогого, предлагаем вам список программ с открытым исходным кодом, которые каждый день доказывают свою ценность в сетях любого размера. От обнаружения устройств, мониторинга сетевого оборудования и серверов до выявления тенденций в функционировании сети, графического представления результатов мониторинга и даже создания резервных копий конфигураций коммутаторов и маршрутизаторов — эти семь бесплатных утилит, скорее всего, смогут приятно удивить вас.
Cacti
Сначала был MRTG (Multi Router Traffic Grapher) — программа для организации сервиса мониторинга сети и измерения данных с течением времени. Еще в 1990-х, его автор Тобиас Отикер (Tobias Oetiker) счел нужным написать простой инструмент для построения графиков, использующий кольцевую базу данных, изначально используемый для отображения пропускной способности маршрутизатора в локальной сети. Так MRTG породил RRDTool, набор утилит для работы с RRD (Round-robin Database, кольцевой базой данных), позволяющий хранить, обрабатывать и графически отображать динамическую информацию, такую как сетевой трафик, загрузка процессора, температура и так далее. Сейчас RRDTool используется в огромном количестве инструментов с открытым исходным кодом. Cacti — это современный флагман среди программного обеспечения с открытым исходным кодом в области графического представления сети, и он выводит принципы MRTG на принципиально новый уровень.
От использования диска до скорости вентилятора в источнике питания, если показатель можно отслеживать, Cacti сможет отобразить его и сделать эти данные легкодоступными.
Cacti — это бесплатная программа, входящее в LAMP-набор серверного программного обеспечения, которое предоставляет стандартизированную программную платформу для построения графиков на основе практически любых статистических данных. Если какое-либо устройство или сервис возвращает числовые данные, то они, скорее всего, могут быть интегрированы в Cacti. Существуют шаблоны для мониторинга широкого спектра оборудования — от Linux- и Windows-серверов до маршрутизаторов и коммутаторов Cisco, — в основном все, что общается на SNMP (Simple Network Management Protocol, простой протокол сетевого управления). Существуют также коллекции шаблонов от сторонних разработчиков, которые еще больше расширяют и без того огромный список совместимых с Cacti аппаратных средств и программного обеспечения.
Несмотря на то, что стандартным методом сбора данных Cacti является протокол SNMP, также для этого могут быть использованы сценарии на Perl или PHP. Фреймворк программной системы умело разделяет на дискретные экземпляры сбор данных и их графическое отображение, что позволяет с легкостью повторно обрабатывать и реорганизовывать существующие данные для различных визуальных представлений. Кроме того, вы можете выбрать определенные временные рамки и отдельные части графиков просто кликнув на них и перетащив.
Кроме того, вы можете выбрать определенные временные рамки и отдельные части графиков просто кликнув на них и перетащив.
Так, например, вы можете быстро просмотреть данные за несколько прошлых лет, чтобы понять, является ли текущее поведение сетевого оборудования или сервера аномальным, или подобные показатели появляются регулярно. А используя Network Weathermap, PHP-плагин для Cacti, вы без чрезмерных усилий сможете создавать карты вашей сети в реальном времени, показывающие загруженность каналов связи между сетевыми устройствами, реализуемые с помощью графиков, которые появляются при наведении указателя мыши на изображение сетевого канала. Многие организации, использующие Cacti, выводят эти карты в круглосуточном режиме на 42-дюймовые ЖК-мониторы, установленные на стене, позволяя ИТ-специалистам мгновенно отслеживать информацию о загруженности сети и состоянии канала.
Таким образом, Cacti — это инструментарий с обширными возможностями для графического отображения и анализа тенденций производительности сети, который можно использовать для мониторинга практически любой контролируемой метрики, представляемой в виде графика. Данное решение также поддерживает практически безграничные возможности для настройки, что может сделать его чересчур сложным при определенных применениях.
Данное решение также поддерживает практически безграничные возможности для настройки, что может сделать его чересчур сложным при определенных применениях.
Nagios
Nagios — это состоявшаяся программная система для мониторинга сети, которая уже многие годы находится в активной разработке. Написанная на языке C, она позволяет делать почти все, что может понадобится системным и сетевым администраторам от пакета прикладных программ для мониторинга. Веб-интерфейс этой программы является быстрым и интуитивно понятным, в то время его серверная часть — чрезвычайно надежной.
Nagios может стать проблемой для новичков, но довольно сложная конфигурация также является преимуществом этого инструмента, так как он может быть адаптирован практически к любой задаче мониторинга.
Как и Cacti, очень активное сообщество поддерживает Nagios, поэтому различные плагины существуют для огромного количества аппаратных средств и программного обеспечения. От простейших ping-проверок до интеграции со сложными программными решениями, такими как, например, написанным на Perl бесплатным программным инструментарием WebInject для тестирования веб-приложений и веб сервисов. Nagios позволяет осуществлять постоянный мониторинг состояния серверов, сервисов, сетевых каналов и всего остального, что понимает протокол сетевого уровня IP. К примеру, вы можете контролировать использование дискового пространства на сервере, загруженность ОЗУ и ЦП, использования лицензии FLEXlm, температуру воздуха на выходе сервера, задержки в WAN и Интеренет-канале и многое другое.
Nagios позволяет осуществлять постоянный мониторинг состояния серверов, сервисов, сетевых каналов и всего остального, что понимает протокол сетевого уровня IP. К примеру, вы можете контролировать использование дискового пространства на сервере, загруженность ОЗУ и ЦП, использования лицензии FLEXlm, температуру воздуха на выходе сервера, задержки в WAN и Интеренет-канале и многое другое.
Очевидно, что любая система мониторинга серверов и сети не будет полноценной без уведомлений. У Nagios с этим все в порядке: программная платформа предлагает настраиваемый механизм уведомлений по электронной почте, через СМС и мгновенные сообщения большинства популярных Интернет-мессенджеров, а также схему эскалации, которая может быть использована для принятия разумных решений о том, кто, как и при каких обстоятельствах должен быть уведомлен, что при правильной настройке поможет вам обеспечить многие часы спокойного сна. А веб-интерфейс может быть использован для временной приостановки получения уведомлений или подтверждения случившейся проблемы, а также внесения заметок администраторами.
Кроме того, функция отображения демонстрирует все контролируемые устройства в логическом представлении их размещения в сети, с цветовым кодированием, что позволяет показать проблемы по мере их возникновения.
Недостатком Nagios является конфигурация, так как ее лучше всего выполнять через командную строку, что значительно усложняет обучение новичков. Хотя люди, знакомые со стандартными файлами конфигурации Linux/Unix, особых проблем испытать не должны.
Возможности Nagios огромны, но усилия по использованию некоторых из них не всегда могут стоить затраченных на это усилий. Но не позволяйте сложностям запугать вас: преимущества системы раннего предупреждения, предоставляемые этим инструментом для столь многих аспектов сети, сложно переоценить.
Icinga
Icinga начиналась как ответвление от системы мониторинга Nagios, но недавно была переписана в самостоятельное решение, известное как Icinga 2. На данный момент обе версии программы находятся в активной разработке и доступны к использованию, при этом Icinga 1. x совместима с большим количеством плагинами и конфигурацией Nagios. Icinga 2 разрабатывалась менее громоздкой, с ориентацией на производительность, и более удобной в использовании. Она предлагает модульную архитектуру и многопоточный дизайн, которых нет ни в Nagios, ни в Icinga 1.
x совместима с большим количеством плагинами и конфигурацией Nagios. Icinga 2 разрабатывалась менее громоздкой, с ориентацией на производительность, и более удобной в использовании. Она предлагает модульную архитектуру и многопоточный дизайн, которых нет ни в Nagios, ни в Icinga 1.
Icinga предлагает полноценную программную платформу для мониторинга и системы оповещения, которая разработана такой же открытой и расширяемой, как и Nagios, но с некоторыми отличиями в веб-интерфейсе.
Как и Nagios, Icinga может быть использована для мониторинга всего, что говорит на языке IP, настолько глубоко, насколько вы можете использовать SNMP, а также настраиваемые плагины и дополнения.
Существует несколько вариаций веб-интерфейса для Icinga, но главным отличием этого программного решения для мониторинга от Nagios является конфигурация, которая может быть выполнена через веб-интерфейс, а не через файлы конфигурации. Для тех, кто предпочитает управлять своей конфигурацией вне командной строки, эта функциональность станет настоящим подарком.
Icinga интегрируется со множеством программных пакетов для мониторинга и графического отображения, таких как PNP4Nagios, inGraph и Graphite, обеспечивая надежную визуализацию вашей сети. Кроме того, Icinga имеет расширенные возможности отчетности.
NeDi
Если вам когда-либо приходилось для поиска устройств в вашей сети подключаться через протокол Telnet к коммутаторам и выполнять поиск по MAC-адресу, или вы просто хотите, чтобы у вас была возможность определить физическое местоположение определенного оборудования (или, что, возможно, еще более важно, где оно было расположено ранее), тогда вам будет интересно взглянуть на NeDi.
NeDi постоянно просматривает сетевую инфраструктуру и каталогизирует устройства, отслеживая все, что обнаружит.
NeDi — это бесплатное программное обеспечение, относящее к LAMP, которое регулярно просматривает MAC-адреса и таблицы ARP в коммутаторах вашей сети, каталогизируя каждое обнаруженное устройство в локальной базе данных. Данный проект не является столь хорошо известным, как некоторые другие, но он может стать очень удобным инструментом при работе с корпоративными сетями, где устройства постоянно меняются и перемещаются.
Данный проект не является столь хорошо известным, как некоторые другие, но он может стать очень удобным инструментом при работе с корпоративными сетями, где устройства постоянно меняются и перемещаются.
Вы можете через веб-интерфейс NeDi задать поиск для определения коммутатора, порта коммутатора, точки доступа или любого другого устройства по MAC-адресу, IP-адресу или DNS-имени. NeDi собирает всю информацию, которую только может, с каждого сетевого устройства, с которым сталкивается, вытягивая с них серийные номера, версии прошивки и программного обеспечения, текущие временные параметры, конфигурации модулей и т. д. Вы даже можете использовать NeDi для отмечания MAC-адресов устройств, которые были потеряны или украдены. Если они снова появятся в сети, NeDi сообщит вам об этом.
Обнаружение запускается процессом cron с заданными интервалами. Конфигурация простая, с единственным конфигурационным файлом, который позволяет значительно повысить количество настроек, в том числе возможность пропускать устройства на основе регулярных выражений или заданных границ сети. NeDi, обычно, использует протоколы Cisco Discovery Protocol или Link Layer Discovery Protocol для обнаружения новых коммутаторов и маршрутизаторов, а затем подключается к ним для сбора их информации. Как только начальная конфигурация будет установлена, обнаружение устройств будет происходить довольно быстро.
NeDi, обычно, использует протоколы Cisco Discovery Protocol или Link Layer Discovery Protocol для обнаружения новых коммутаторов и маршрутизаторов, а затем подключается к ним для сбора их информации. Как только начальная конфигурация будет установлена, обнаружение устройств будет происходить довольно быстро.
До определенного уровня NeDi может интегрироваться с Cacti, поэтому существует возможность связать обнаружение устройств с соответствующими графиками Cacti.
Ntop
Проект Ntop — сейчас для «нового поколения» более известный как Ntopng — прошел долгий путь развития за последнее десятилетие. Но назовите его как хотите — Ntop или Ntopng, — в результате вы получите первоклассный инструмент для мониторинга сетевого траффика в паре с быстрым и простым веб-интерфейсом. Он написан на C и полностью самодостаточный. Вы запускаете один процесс, настроенный на определенный сетевой интерфейс, и это все, что ему нужно.
Ntop — это инструмент для анализа пакетов с легким веб-интерфейсом, который показывает данные в реальном времени о сетевом трафике. Информация о потоке данных через хост и о соединении с хостом также доступны в режиме реального времени.
Информация о потоке данных через хост и о соединении с хостом также доступны в режиме реального времени.
Ntop предоставляет легко усваиваемые графики и таблицы, показывающие текущий и прошлый сетевой трафик, включая протокол, источник, назначение и историю конкретных транзакций, а также хосты с обоих концов. Кроме того, вы найдете впечатляющий набор графиков, диаграмм и карт использования сети в реальном времени, а также модульную архитектуру для огромного количества надстроек, таких как добавление мониторов NetFlow и sFlow. Здесь вы даже сможете обнаружить Nbox — аппаратный монитор, который встраивает в Ntop.
Кроме того, Ntop включает API-интерфейс для скриптового языка программирования Lua, который может быть использован для поддержки расширений. Ntop также может хранить данные хоста в файлах RRD для осуществления постоянного сбора данных.
Одним из самых полезных применений Ntopng является контроль трафика в конкретном месте. К примеру, когда на вашей карте сети часть сетевых каналов подсвечены красным, но вы не знаете почему, вы можете с помощью Ntopng получить поминутный отчет о проблемном сегменте сети и сразу узнать, какие хосты ответственны за проблему.
Пользу от такой видимости сети сложно переоценить, а получить ее очень легко. По сути, вы можете запустить Ntopng на любом интерфейсе, который был настроен на уровне коммутатора, для мониторинга другого порта или VLAN. Вот и все.
Zabbix
Zabbix — это полномасштабный инструмент для сетевого и системного мониторинга сети, который объединяет несколько функций в одной веб-консоли. Он может быть сконфигурирован для мониторинга и сбора данных с самых разных серверов и сетевых устройств, обеспечивая обслуживание и мониторинг производительности каждого объекта.
Zabbix позволяет производить мониторинг серверов и сетей с помощью широкого набора инструментов, включая мониторинг гипервизоров виртуализации и стеков веб-приложений.
В основном, Zabbix работает с программными агентами, запущенными на контролируемых системах. Но это решение также может работать и без агентов, используя протокол SNMP или другие возможности для осуществления мониторинга. Zabbix поддерживает VMware и другие гипервизоры виртуализации, предоставляя подробные данные о производительности гипервизора и его активности. Особое внимание также уделяется мониторингу серверов приложений Java, веб-сервисов и баз данных.
Zabbix поддерживает VMware и другие гипервизоры виртуализации, предоставляя подробные данные о производительности гипервизора и его активности. Особое внимание также уделяется мониторингу серверов приложений Java, веб-сервисов и баз данных.
Хосты могут добавляться вручную или через процесс автоматического обнаружения. Широкий набор шаблонов по умолчанию применяется к наиболее распространенным вариантам использования, таким как Linux, FreeBSD и Windows-сервера; широко-используемые службы, такие как SMTP и HTTP, а также ICMP и IPMI для подробного мониторинга аппаратной части сети. Кроме того, пользовательские проверки, написанные на Perl, Python или почти на любом другом языке, могут быть интегрированы в Zabbix.
Zabbix позволяет настраивать панели мониторинга и веб-интерфейс, чтобы сфокусировать внимание на наиболее важных компонентах сети. Уведомления и эскалации проблем могут основываться на настраиваемых действиях, которые применяются к хостам или группам хостов. Действия могут даже настраиваться для запуска удаленных команд, поэтому некий ваш сценарий может запускаться на контролируемом хосте, если наблюдаются определенные критерии событий.
Программа отображает в виде графиков данные о производительности, такие как пропускная способность сети и загрузка процессора, а также собирает их для настраиваемых систем отображения. Кроме того, Zabbix поддерживает настраиваемые карты, экраны и даже слайд-шоу, отображающие текущий статус контролируемых устройств.
Zabbix может быть сложным для реализации на начальном этапе, но разумное использование автоматического обнаружения и различных шаблонов может частично облегчить трудности с интеграцией. В дополнение к устанавливаемому пакету, Zabbix доступен как виртуальное устройство для нескольких популярных гипервизоров.
Observium
Observium — это программа для мониторинга сетевого оборудования и серверов, которое имеет огромный список поддерживаемых устройств, использующих протокол SNMP. Как программное обеспечение, относящееся к LAMP, Observium относительно легко устанавливается и настраивается, требуя обычных установок Apache, PHP и MySQL, создания базы данных, конфигурации Apache и тому подобного. Он устанавливается как собственный сервер с выделенным URL-адресом.
Он устанавливается как собственный сервер с выделенным URL-адресом.
Observium сочетает в себе мониторинг систем и сетей с анализом тенденций производительности. Он может быть настроен для отслеживания практически любых показателей.
Вы можете войти в графический интерфейс и начать добавлять хосты и сети, а также задать диапазоны для автоматического обнаружения и данные SNMP, чтобы Observium мог исследовать окружающие его сети и собирать данные по каждой обнаруженной системе. Observium также может обнаруживать сетевые устройства через протоколы CDP, LLDP или FDP, а удаленные агенты хоста могут быть развернуты на Linux-системах, чтобы помочь в сборе данных.
Все эта собранная информация доступна через легкий в использовании пользовательский интерфейс, который предоставляет продвинутые возможности для статистического отображения данных, а также в виде диаграмм и графиков. Вы можете получить что угодно: от времени отклика ping и SNMP до графиков пропускной способности, фрагментации, количества IP-пакетов и т. д. В зависимости от устройства, эти данные могут быть доступны вплоть для каждого обнаруженного порта.
д. В зависимости от устройства, эти данные могут быть доступны вплоть для каждого обнаруженного порта.
Что касается серверов, то для них Observium может отобразить информацию о состоянии центрального процессора, оперативной памяти, хранилища данных, свопа, температуры и т. д. из журнала событий. Вы также можете включить сбор данных и графическое отображение производительности для различных сервисов, включая Apache, MySQL, BIND, Memcached, Postfix и другие.
Observium отлично работает как виртуальная машина, поэтому может быстро стать основным инструментом для получения информации о состоянии серверов и сетей. Это отличный способ добавить автоматическое обнаружение и графическое представление в сеть любого размера.
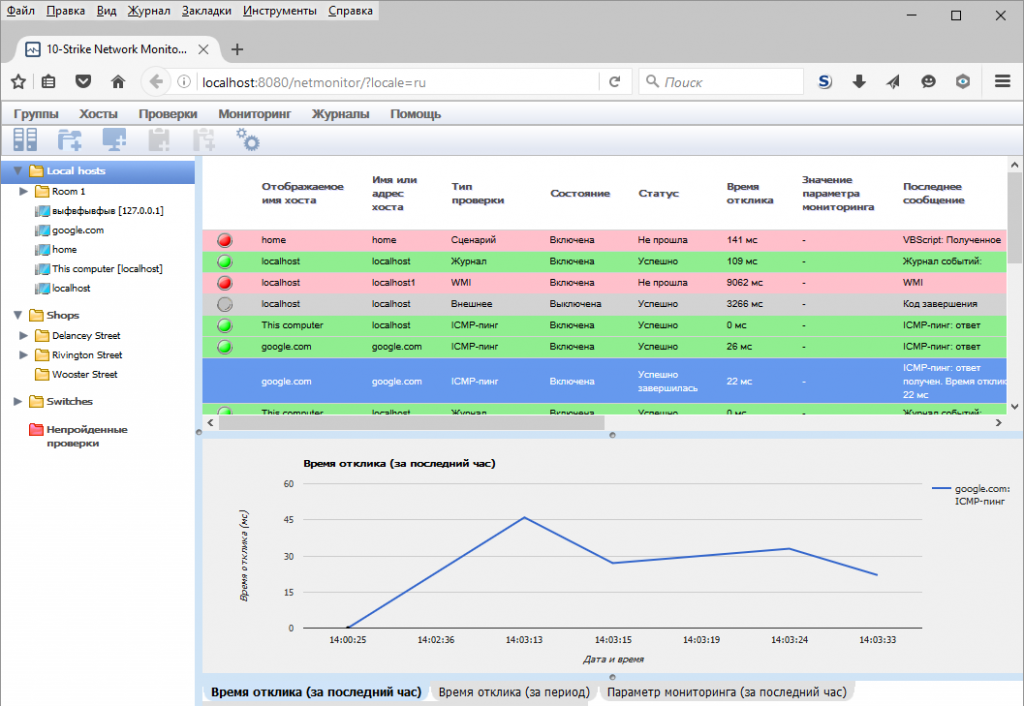
Мониторинг сети своими руками
Слишком часто ИТ-администраторы считают, что они ограничены в своих возможностях. Независимо от того, имеем ли мы дело с пользовательским программным приложением или «неподдерживаемой» частью аппаратного обеспечения, многие из нас считают, что если система мониторинга не сможет сразу же справиться с ним, то получить в этой ситуации необходимые данные невозможно. Это, конечно же, не так. Приложив немного усилий, вы сможете почти все сделать более видимым, учтенным и контролируемым.
Это, конечно же, не так. Приложив немного усилий, вы сможете почти все сделать более видимым, учтенным и контролируемым.
В качестве примера можно привести пользовательское приложение с базой данных на серверной части, например, интернет-магазин. Ваш менеджмент хочет увидеть красивые графики и диаграммы, оформленные то в одном виде, то в другом. Если вы уже используете, скажем, Cacti, у вас есть несколько возможностей вывести собранные данные в требуемом формате. Вы можете, к примеру, написать простой скрипт на Perl или PHP для запуска запросов в базе данных и передачи этих расчетов в Cacti либо же использовать SNMP-вызов к серверу базы данных, используя частный MIB (Management Information Base, база управляющей информации). Так или иначе, но задача может быть выполнена, и выполнена легко, если у вас есть необходимый для этого инструментарий.
Получить доступ к большинству из приведенных в данной статье бесплатных утилит для мониторинга сетевого оборудования не должно быть сложно. У них есть пакетные версии, доступные для загрузки для наиболее популярных дистрибутивов Linux, если только они изначально в него не входят. В некоторых случаях они могут быть предварительно сконфигурированы как виртуальный сервер. В зависимости от размера вашей инфраструктуры, конфигурирование и настройка этих инструментов может занять довольно много времени, но как только они заработают, они станут надежной опорой для вас. В крайнем случае, стоит хотя бы протестировать их.
У них есть пакетные версии, доступные для загрузки для наиболее популярных дистрибутивов Linux, если только они изначально в него не входят. В некоторых случаях они могут быть предварительно сконфигурированы как виртуальный сервер. В зависимости от размера вашей инфраструктуры, конфигурирование и настройка этих инструментов может занять довольно много времени, но как только они заработают, они станут надежной опорой для вас. В крайнем случае, стоит хотя бы протестировать их.
Независимо от того, какую из этих вышеперечисленных систем вы используете, чтобы следить за своей инфраструктурой и оборудованием, она предоставит вам как минимум функциональные возможности еще одного системного администратора. Она хоть не может ничего исправить, но будет следить буквально за всем в вашей сети круглые сутки и семь дней в неделю. Предварительно потраченное время на установку и настройку окупятся с лихвой. Кроме того, обязательно запустите небольшой набор автономных средств мониторинга на другом сервере, чтобы наблюдать за основным средством мониторинга. Это то случай, когда всегда лучше следить за наблюдателем.
Это то случай, когда всегда лучше следить за наблюдателем.
Появились вопросы или нужна консультация? Обращайтесь!
Вечный параноик, Антон Кочуков.
См. также:
5 лучших бесплатных систем мониторинга ИТ-инфраструктуры
Практикум /
Бизнес нуждается в системах для мониторинга ИТ-инфраструктуры, чтобы обеспечить запуск и последующую работу необходимых ему сетевых систем и сервисов. Однако осуществление мониторинга различных составных частей ИТ-инфраструктуры может стать для вас настоящей головной болью, если вы не смогли для этих целей выбрать подходящее правильное решение. Независимо от масштабов управляемой вами инфраструктуры, будь она небольшого размера или уровня предприятия, вы в любом случае не сможете обойтись без надежного инструментария для мониторинга. Даже если вы просто владелец персонального сайта, вы все равно нуждаетесь в круглосуточном мониторинге доступности вашего ресурса.
Существует многоженство программных продуктов, как коммерческих, так и бесплатных (с открытым исходным кодом), которые могут помочь вам осуществлять мониторинг вашей ИТ инфраструктуры и уведомлять о любых сбоях. Учитывая большое количество предложений на рынке, не просто найти нужный вам вариант, который впишется в ваш ценовой диапазон. Хорошие новости для многих из нас заключаются в том, что на рынке доступны мощные решения для мониторинга ИТ-инфраструктуры с открытым исходным кодом. Спасибо сообществам разработчиков программного обеспечения с открытым исходным кодом за их работу.
Давайте взглянем на лучшие варианты из доступных на рынке бесплатных систем мониторинга ИТ-инфраструктуры и определим, что подойдет вам.
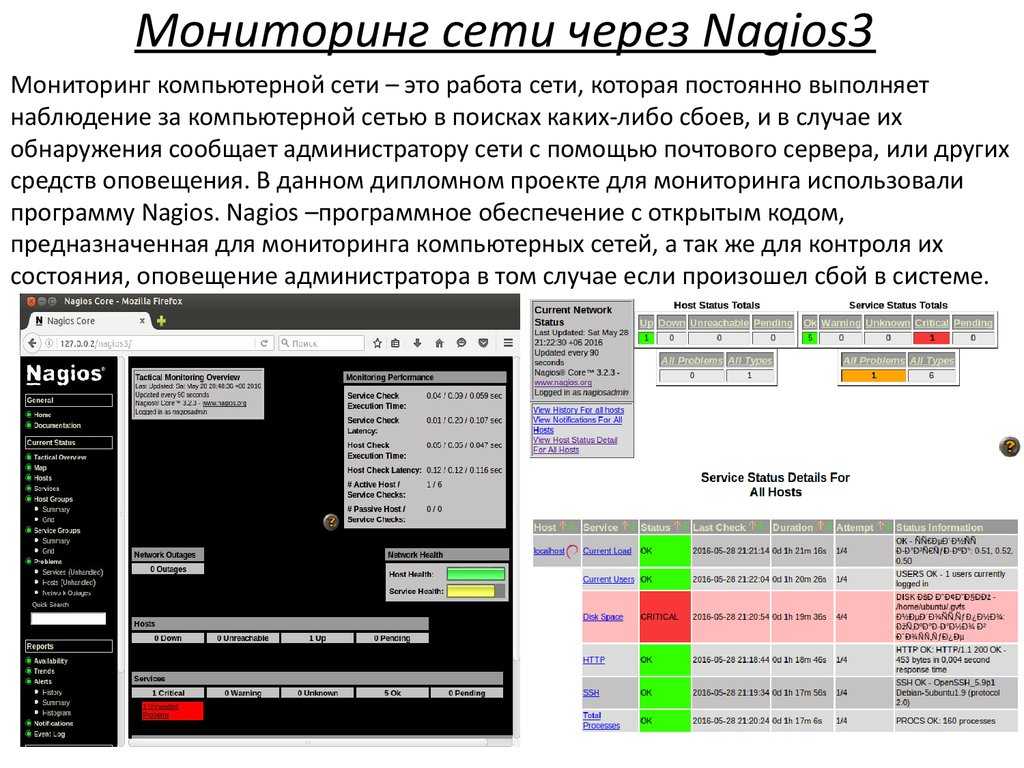
1. Nagios
Сообщество Nagios (https://www.nagios.org/), ведущее свою историю с 1999 года, является одним из лидеров отрасли в области решений для мониторинга ИТ-инфраструктуры любого масштаба — от малого до корпоративного уровня.
Программное решение для мониторинга компьютерных систем и сетей Nagios способно осуществлять мониторинг практически любых компонентов, включая сетевые протоколы, операционные системы, системные показатели, приложения, службы, веб-сервера, веб-сайты, связующее программное обеспечение (Middleware) и т. д..
д..
Базовая функциональность системы для мониторинга Nagios реализована на ядре Core 4, который обеспечивает высокий уровень производительности за счет меньшего потребления ресурсов сервера.
Вы можете, используя плагин, интегрировать его практически с любым типом стороннего программного обеспечения, причем, скорее всего, этот плагин кто-то уже написал (https://www.nagios.org/projects/nagios-plugins/).
Если вы используете связующее программное обеспечение (Middleware), вы можете использовать Nagios для мониторинга WebLogic, WebSphere, JBoss, Tomcat, Apache, URL, Nginx и т. д..
Краткий перечень доступных возможностей:
- Централизованное видение всей контролируемой ИТ-инфраструктуры.
- Автоматический перезапуск приложений, осуществляемый обработчиком событий, если в работе этих приложений обнаружен сбой.
- Многопользовательский доступ.
- Ограниченный доступ позволяет управлять видимостью для пользователей только теми компонентами ИТ-инфраструктуры, которые напрямую связаны с их зоной ответственности.

- Сообщество Nagios насчитывает более 1 млн. активных пользователей.
- Расширяемая архитектура.
2. Zabbix
Система мониторинга служб и состояний компьютерной сети Zabbix (https://www.zabbix.com/) — это великолепное бесплатное программное обеспечение уровня предприятия, предназначенное для осуществления мониторинга всего: от производительности и доступности серверов и сетевого оборудования до веб-приложений и базы данных.
Zabbix используется тысячами компаний по всему миру, включая DELL, Salesforce, ICANN, Orange и т. д.
Системная архитектура Zabbix опирается на использование центрального сервера (ядро системы, которое дистанционно контролирует сетевые сервисы, содержит все конфигурационные, статистические и оперативные данные, а также оповещает о проблемах с контролируемым оборудованием) и агентов (программная составляющая контроля локальных ресурсов и приложений на сетевых системах). В большинстве случаев Zabbix-агенты изначально инсталлируются и должны быть запущены на сетевых системах, чтобы вы могли иметь доступ к таким данным, как информация о нагрузке процессора, использовании сети, дисковом пространстве и т. д.. Однако, вам не нужно устанавливать Zabbix -агент для проверки доступности и реакции таких стандартных сервисов, как FTP, SSH, HTTP, DNS и т. д..
д.. Однако, вам не нужно устанавливать Zabbix -агент для проверки доступности и реакции таких стандартных сервисов, как FTP, SSH, HTTP, DNS и т. д..
Zabbix-сервер и Zabbix-агент могут быть установлены на такие платформы, как Linux, AIX, Solaris, MacOS X, FreeBSD, OpenBSD, HP-UX и т. д., кроме того, реализована поддержка агентов для установки на решения на базе операционных систем семейства Windows.
Кроме того, Zabbix поддерживает осуществление мониторинга через SNMP (Simple Network Management Protocol, Простой протокол сетевого управления) и предоставляет лучшую отчетность.
Краткий перечень доступных возможностей:
- Мониторинг Java-серверов приложений напрямую через технологию JMX (Java Management Extensions, Управленческие расширения Java).
- Пользовательский интерфейс Zabbix на стороне клиента защищен от атак методом грубой силы.
- Расширение функциональности за счет поддержки внешних скриптов, написанных на разных языках, таких как Ruby, Python, Perl, PHP, Java, а также сценариев командной строки (shell scripts).
- Интеграция с другими программными инструментами для системного менеджмента, такими как Puppet, cfengine, Chef, bcfg2 и некоторыми другими.

Если вы хотите больше узнать о том, как использовать Zabbix для крупных организаций, вы можете пройти курс он-лайн обучения от Packt Publishing (https://www.udemy.com/zabbix-network-monitoring-essentials/).
3. Cacti
Приложение для мониторинга сети Cacti (https://www.cacti.net/) — это еще один программный инструмент с открытым исходным кодом для мониторинга сети, который может быть установлен на Linux или Windows. Он собирает различные статистические данные за определенные временные интервалы и позволяет отобразить их в графическом виде при помощи набора утилит RRDTool.
Cacti работает с SNMP и представляет сетевую статистику в виде простых для понимания графиков.
Cacti требуется MySQL, Apache или IIS с поддержкой PHP.
Краткий перечень доступных возможностей:
- Неограниченное количество элементов отображения графика может быть задано, как через опцию создания функций CDEF (позволяет применять различные математические функции к графику для изменения выходных данных), так и используя шаблоны графиков из Cacti.
- Поддержка автоматического заполнения для графиков.
- Поддержка файлов RRD (Round-Robin Database, Циклическая база данных) с более чем одним источником данных, а также использование RRD-файлов, хранящихся в любом месте локальной файловой системы.
- Ориентированное на пользователя управление и безопасность.
- Скрипты для выборочного сбора пользовательских данных.
4. OpenNMS
Высокоуровневая программная платформа для мониторинга сетей и сетевых устройств OpenNMS (https://www.opennms.org/en) позволит вам создать решение сетевого мониторинга для любой ИТ-инфраструктуры промышленного масштаба. Вы можете собирать системные показатели с помощью JMX, WMI, SNMP, NRPE, XML HTTP, JDBC, XML, JSON и т. д.
С помощью OpenNMS вы можете в вашей сети, как обнаруживать связи сетевых топологий на втором уровне модели OSI, так и отслеживать неполадки в маршрутизации на уровне 3. Эта система мониторинга не использует агентов, а построена на событийно-ориентированной архитектуре, а также поддерживает работу в связке с системой агрегации данных и отображения графиков в реальном времени Grafana.
OpenNMS имеет встроенные модули формирования отчетности, а это означает, что вы можете просматривать отчеты в виде красивых дашбордов (dashboard, аналитических информационных панелей) и диаграмм. В целом, OpenNMS получил прекрасный пользовательский интерфейс.
Вы также можете установить OpenNMS в Docker — программный инструментарий для управления изолированными Linux-контейнерами.
Краткий перечень доступных возможностей:
- OpenNMS специально разрабатывался для Linux, но также имеется реализованная поддержка Windows, Solaris и OSX.
- Мониторинг температуры устройств.
- Настраивая информационная панель администратора.
- Мониторинг электроснабжения.
- Поддержка IPv4 и IPv6.
- Настройка формирования уведомлений о событиях и их отправка по электронной почте, СМС, XMPP (расширяемый протокол обмена сообщениями и информацией о присутствии, ранее известный как Jabber) и другими способами.
- Географическая карта сетевых узлов для отображения местоположения «проблемных» узлов и перебоев в предоставлении услуг с использованием карт таких картографических порталов, как Open Street Map, Google Maps или Mapquest.
5. Icinga
Бесплатная программная система для мониторинга компьютерных систем и сетей Icinga (https://icinga.com/) позволит вам осуществлять мониторинг всех доступных систем в вашей сети. Она поддерживает различные способы предупреждений, а также предоставит вам базу данных для ваших отчетов об уровне обслуживания.
Icinga, история которой началась в 2009 году, как ответвление от системы мониторинга Nagios, с выходом Icinga версии 2 смогла полностью освободиться от «оков» ядра Nagios, став быстрее, проще в настройке и значительно лучшее масштабируемой.
Краткий перечень доступных возможностей:
- Мониторинг состояния сетевых сервисов, серверных компонентов, а также принтеров, маршрутизаторов и т. д.
- Осуществление мониторинга с помощью плагинов Icinga 2.
- Поддержка обработчиков событий и создания уведомлений.
- Отправка уведомлений по электронной почте, СМС, а также через различные службы мгновенных сообщений.
- Кроссплатформенная поддержка различных операционных систем.
- Параллельные проверки сервисов.
- Возможность выбора между классическим пользовательским интерфейсом и веб.
- Формирование отчетов на основе шаблонов.
Выводы
Таким образом, если ваш бюджет уперся в серьезные финансовые ограничения, то вышеперечисленное программное обеспечение для сетевого мониторинга все равно сможет помочь вам наладить контроль над различными аспектами вашей ИТ-инфраструктуры. Все эти системы доступны бесплатно, поэтому вы можете загрузить их и начать свое знакомство с ними уже сегодня.
Вступайте в Telegram канал проекта
NetworkGuru, чтобы не пропустить интересные статьи и вебинары.
Подписывайтесь на рассылку, делитесь статьями в соцсетях и задавайте вопросы в комментариях!
Вечный параноик, Антон Кочуков.
См. также:
также:
Лучшее программное обеспечение для мониторинга сети на 2022 год
Туманные пять часов утра, и внезапно несколько ключевых серверов в вашей сети выходят из строя. Вы заняты сном, поэтому вы не узнаете об этом, пока ваши пользователи не войдут и не поднимут шум. К тому времени, как вы приедете, у вашего босса будет пена изо рта, и вы ищете, где бы спрятаться. Добро пожаловать в мир IT-менеджера. И нет, теперь, когда мы все работаем из дома из-за пандемии, это не стало проще. Во всяком случае, это стало сложнее, так как вам нужно будет узнать о проблемах и решить их, в то время, когда не так просто зайти в свой шкаф данных. К счастью, инструменты, облегчающие этот процесс, многочисленны и хорошо зарекомендовали себя. Это инструменты сетевого мониторинга общего назначения, и мы протестировали и оценили лучших игроков.
Paessler PRTG Network Monitor
Лучшее решение для расширенного мониторинга
4.5 Выдающееся
Практический результат:
Если вы понимаете, какую инфраструктуру вам нужно отслеживать, и не возражаете против структуры лицензирования, PRTG является мощный и даже удобный продукт. Хотя набор функций может быть немного ошеломляющим, ИТ-специалистам будет сложно обойтись без опций.
Хотя набор функций может быть немного ошеломляющим, ИТ-специалистам будет сложно обойтись без опций.
ПРОФИ
- Очень расширяемый
- Глубокая поддержка большинства устройств
ПРОТИВ
- Лицензирование на основе датчиков может стать дорогим
- Требуется выделенный локальный сервер
Progress WhatsUp Gold
Лучшее решение для основной инфраструктуры
4.5 Выдающееся
Итог:
Progress WhatsUp Gold обеспечивает превосходный баланс между визуальным эффектом и способностью отслеживать распространенные сетевые устройства. Хотя расширяемые плагины не так свободно доступны, как у некоторых конкурентов, основной продукт в большинстве случаев более чем компенсирует это.
ПРОФИ
- Элегантный и интуитивно понятный пользовательский интерфейс
- Использует безагентную модель, охватывающую наиболее широко используемые протоколы управления.
- Множество готовых типов предупреждений
ПРОТИВ
- Должен быть установлен в помещении
- Должен быть развернут в среде Windows
| Продан | Список цен | Цена | |
|---|---|---|---|
| WhatsUp Gold | Посетить сайт | Посетить сайт |
Видеть это |
| Консультации по программному обеспечению | Сравнивать цены | Сравнивать цены |
Видеть это |
Прочитайте наш обзор WhatsUp Gold
LogicMonitor
Лучшее решение для широкораспределенных сетей
4. 0 Отлично
0 Отлично
Итог:
Если ваши устройства географически распределены и все ваши сайты подключены к Интернету, трудно найти решение лучше, чем Logic Monitor. Для небольших сетей, которые могут быть отгорожены от Интернета, вам нужно будет искать в другом месте.
ПРОФИ
- Сервис основан на облаке
- Безагентная работа
- Богатый и полезный пользовательский интерфейс
ПРОТИВ
- Требуется подключение к Интернету
- Оповещения об отсутствии действий в локальной сети
- Ценообразование только с цитатой
| Продан | Список цен | Цена | |
|---|---|---|---|
| ЛогикМонитор | Посетить сайт | Посетить сайт |
Видеть это |
Прочитайте наш обзор LogicMonitor
Nagios XI
Лучшее для настройки и расширения
4. 0 Отлично
0 Отлично
Bottom Line:
Если гибкость и расширяемость — это то, что вам нужно в инструменте мониторинга сети, то Nagios XI — это то, что вам нужно. Простая безагентная модель и неограниченное количество целей лишь слегка омрачены отсутствием дизайнерского блеска.
ПРОФИ
- Чрезвычайно гибкий
- Массивное сообщество пользователей
- Плагины легко писать
ПРОТИВ
- Устаревший интерфейс
- Крутая кривая обучения
| Продан | Список цен | Цена | |
|---|---|---|---|
| Нагиос | Начиная с 1995 долларов США за стандартную версию, 3495 долларов США за версию Enterprise. | Начиная с 1995 долларов США за стандартную версию, 3495 долларов США за версию Enterprise. |
Видеть это |
Прочтите наш обзор Nagios XI
NetCrunch
Лучшее решение для визуального мониторинга
4. 0 Отлично
0 Отлично
Итог:
NetCrunch красив и многофункционален, но он не полностью перенял веб-интерфейсы, используемые почти всеми другими продуктами. Хотя в браузере есть некоторая возможность просмотра состояния сети, настоящее удаленное управление в настоящее время невозможно без установки толстого клиента.
ПРОФИ
- Высокая производительность
- Надежные инструменты визуализации
- Тонко настроенный контроль над оповещениями
ПРОТИВ
- Веб-доступу не хватает административных возможностей
- Требуется локальная установка
Datadog
Лучше всего подходит для управления облачными сервисами
3,5 Хорошо
Итог:
Datadog — это очень хорошая служба мониторинга сети и услуг для ИТ-магазинов среднего размера. Если вы сможете пройти первоначальную настройку и архитектуру на основе агентов, вам будет что предложить, включая множество интеграций, информационных панелей и гибких оповещений.
ПРОФИ
- Упрощенная облачная модель
- Поддерживает практически любой сервисный стек
- Обеспечивает глубину, которую оценят поставщики услуг
- Настраиваемые представления, адаптированные для каждого приложения
ПРОТИВ
- В первую очередь не предназначен для мониторинга маршрутизаторов и сетевого оборудования.
- Нет автоматического обнаружения устройств
- Значительный процесс первоначальной настройки из-за архитектуры на основе агентов
- Нет стандартной отчетности
| Продан | Список цен | Цена | |
|---|---|---|---|
| датадог | Посетить сайт | Посетить сайт |
Видеть это (Открывается в новом окне) |
Прочтите наш обзор Datadog
Idera Uptime Infrastructure Monitor
Лучшее решение для агентного мониторинга
3,5 Хорошо
Практический результат:
Idera Uptime Infrastructure Monitor многое делает правильно, и вы, безусловно, найдете большинство функций, которые вам понадобятся, в инструменте управления сетью и устройствами. Но его склонность к сложности и жесткий толчок к использованию агентов могут беспокоить некоторых.
ПРОФИ
- Может быть установлен на Windows или Linux
- Высокий уровень гибкости в оповещениях
- Может использоваться с агентами или без них
МИНУСЫ
- Требуется локальная установка
- Агенты нужны для лучшего опыта
- Некоторые процессы требуют крутой кривой обучения
| Продан | Список цен | Цена | |
|---|---|---|---|
| ИДЕРА | 125,00 долларов США за устройство | 125,00 долларов США за устройство |
Видеть это |
| Консультации по программному обеспечению | Сравнивать цены | Сравнивать цены |
Видеть это |
Прочтите наш обзор Idera Uptime Infrastructure Monitor
ManageEngine OpManager
Лучше всего подходит для распространенных сетевых конфигураций
3. 5 Хорошо
Практический результат:
Практический результат:
Практический результат: OpManager
также предоставляет хорошие возможности управления ИТ-инфраструктурой, в первую очередь, для управления ИТ-инфраструктурой функции управления производительностью и мониторинга сети.
ПРОФИ
- Легко использовать
- Интуитивное создание карты
ПРОТИВ
- Для мониторинга устройств в нескольких сетях требуется обновление до Enterprise Edition.
- Установка по умолчанию не включает отчеты
- Требуется локальная установка
Vallum Halo Manager
Лучше всего подходит для мониторинга работоспособности небольших сетей
2.5 Удовлетворительно
Практический результат:
Vallum Halo Manager — это недорогой инструмент, который может работать в элементарных сетях. Однако, если вам нужно проявлять инициативу и иметь более глубокое представление о более крупной сети, вам нужно искать в другом месте.
ПРОФИ
- Не требуется помощь для установки
- Бесплатно для устройств младше 15 лет
ПРОТИВ
- Отсутствие надежной функции отчетности
- Ограниченные возможности оповещения
| Продан | Список цен | Цена | |
|---|---|---|---|
| Программное обеспечение Валлум | $895,00 | $895,00 |
Видеть это |
| Консультации по программному обеспечению | Сравнивать цены | Сравнивать цены |
Видеть это |
Прочитайте наш обзор Vallum Halo Manager
Руководство по покупке: лучшее программное обеспечение для мониторинга сети на 2022 год
Что такое инструмент мониторинга сети?
Существует две основные категории инструментов мониторинга. Первая — это так называемая безагентная платформа. Обычно это устанавливается в помещении, то есть на сервере или рабочей станции, которые физически подключены к вашей сети. Этому анализатору также потребуются все учетные данные для доступа к каждой из систем и служб, которые вы хотите отслеживать. Преимущество этого подхода в том, что его не нужно устанавливать на каждое отдельное устройство, и он может автоматически обнаруживать и классифицировать устройства в вашей сети с минимальными усилиями с вашей стороны. Недостатком является то, что вам обычно требуется выделенная система с достаточной мощностью для запуска программного обеспечения и поддерживающей его базы данных; и если у вас больше одного офиса, вам наверняка понадобится такая мускулистая машина в каждом из них.
Другой метод — система на основе агентов. Они, как правило, предоставляют большую часть решения в модели «программное обеспечение как услуга» (SaaS), что просто означает, что вы будете получать доступ к программному обеспечению через Интернет (хотя это может вывести соображения безопасности на первый план в зависимости от бизнес). Агенты или программы мониторинга, которые находятся на каждом отдельном устройстве, будут запускаться и сообщать о важной телеметрии. Преимущество этого метода заключается в том, что вы обычно можете получить более подробные данные, чем при использовании безагентной системы, поскольку агенты, как правило, имеют более высокий уровень доступа к оборудованию. Недостатком является то, что приложение агента необходимо будет установить на каждое отдельное устройство, за которым вы следите, и это может застрять даже при автоматизации. Во-первых, это может вызвать проблемы, если устройства не поддерживают операционные системы, которые требуется установить программному обеспечению агента.
Третий тип инструментов, который мы не включили в этот обзор, — это категория специалиста. Как правило, к ним относятся мониторы безопасности и сканеры, а также анализаторы беспроводных сетей, такие как Ekahau Pro. Возьмем этот продукт в качестве примера, несмотря на то, что он имеет некоторые общие функции с инструментами, которые мы здесь рассмотрели, такие как анализ трафика, но в нем также отсутствуют некоторые функции, такие как веб-интерфейс или удаленное управление. Это потому, что Экахау — специалист; он специально создан для очень конкретной задачи, а именно для конфигурации беспроводной сети в любом масштабе. Это означает, что у него есть несколько возможностей, которые вы не найдете в инструментах, которые мы рассмотрели в рамках этого обзора, потому что они просто не нужны.
(Примечание редактора: Ekahau принадлежит Зиффу Дэвису, материнской компании PCMag.)
Одним из примеров являются планы этажей, сгенерированные с помощью САПР, которые отображают мощность вашего беспроводного сигнала, поскольку они содержат числовые значения, учитывающие плотность стен. , двери и окна и как они влияют на пропускную способность беспроводной сети. Ekahau использует эти данные в собственном картографическом приложении и приложении для точек доступа, чтобы не только контролировать вашу беспроводную сеть, но и генерировать сценарии «что, если» для различных строительных материалов офиса в зависимости от размещения точки доступа. Это замечательно для специалистов по беспроводным сетям, но вы не можете использовать Ekahau для замены комплексного сетевого монитора, когда речь идет о таких вещах, как удаленное состояние устройств для проводной инфраструктуры.
Таким образом, специализированный инструмент может звучать как , как будто он может управлять общим сетевым управлением, но он обычно не может охватывать столько типов устройств и услуг или даже функций управления, как инструменты, которые мы рассмотрели здесь. Однако они будут предлагать удобные функции, которые вы не найдете в этих инструментах, поэтому просто убедитесь, что они вам нужны, и будьте осторожны при добавлении их в свой набор ИТ-инструментов.
(Примечание редактора: Ekahau принадлежит Ziff Davis, материнской компании PCMag.)
Как мы тестируем сетевые анализаторы
Используете ли вы систему с агентом или без агента, есть несколько аспектов, на которые мы обращаем внимание при оценке этих решений. Одной из важнейших составляющих является удобство использования. Независимо от того, насколько сложной может быть часть программного обеспечения, если кривая обучения слишком высока, то это потеря времени, когда ваши устройства не отслеживаются, а ваш ИТ-персонал занимается чем-то другим, кроме управления инфраструктурой. Во многих случаях поддержка и документация играют значительную роль, но бывают и случаи, когда интерфейс явно отстает от других систем того же класса. Вам нужен инструмент, который может быстро понять ИТ-менеджер, знакомый с сетевыми технологиями, чтобы вы могли как можно скорее запустить его в своей сети.
Еще одна очень важная практическая возможность, особенно на ранних этапах развертывания, — это то, как программное обеспечение добавляет устройства. В конце концов, это, по сути, инструменты для мониторинга большого количества различных конечных точек и того, как они работают вместе. Даже малый и средний бизнес (SMB) может иметь в своем центральном офисе не только несколько десятков коммутаторов, маршрутизаторов и даже межсетевых экранов; он также может иметь несколько таких устройств в каждом филиале. Чтобы эффективно контролировать сотни или даже тысячи устройств, вы должны иметь возможность указать программному обеспечению, какие именно устройства вы хотите отслеживать, где они находятся и что вы хотите знать о них.
Вы можете сделать это для каждого устройства отдельно или с помощью так называемого автоматического обнаружения . Это просто относится к способности системы мониторинга сканировать сеть и отчитываться со списком всех найденных устройств. Затем администраторы просто модифицируют те устройства, которые в этом нуждаются, а затем программное обеспечение автоматически добавляет их в свой список отслеживаемых целей. Хотя это, как правило, менее важная проблема в системах на основе агентов, поскольку вам все равно придется устанавливать программное обеспечение на каждую цель мониторинга; для безагентных систем это должно быть как можно более безболезненным, поскольку это большая часть общего процесса установки. В лучших системах по умолчанию используются наиболее часто используемые параметры, но расширенные функции доступны тем пользователям, которым они нужны.
После этого рассмотрим, насколько просто вручную добавлять отдельные устройства. Как правило, ни один процесс автоматического обнаружения не находит все, поэтому вам нужна возможность заставить систему просмотреть конкретное устройство, которое она пропустила во время сканирования. Это должно включать в себя возможность добавлять службы, а также только конечные устройства, такие как проводные и беспроводные маршрутизаторы, коммутаторы и брандмауэры. Их, как правило, немного сложнее контролировать, но они являются одними из самых важных устройств, когда речь идет об общем состоянии любой сети. Вот почему во время тестирования мы относились к этому как к главному соображению.
Не забывайте о программно-определяемых сетях
В наши дни, особенно сейчас, когда многие сети управляются удаленно, очень важна возможность поддержки виртуализированной инфраструктуры и сред программно-определяемых сетей (SDN). Это может включать в себя все, от виртуальных серверов, которые многие из вас установили в общедоступном облаке «инфраструктура как услуга» (IaaS), до даже самых маленьких виртуальных контейнеров, которые вы используете для обслуживания отдельных приложений.
Сегодня даже большинство малых и средних предприятий используют большую часть своих локальных серверов в основном как виртуальные машины (ВМ), живущие в большой экосистеме гипервизора. Это связано с тем, что преимуществ виртуальных машин по сравнению с физическими серверами слишком много, чтобы их игнорировать не только ИТ-менеджеры, но и генеральные и финансовые директора. К ним относятся более низкие затраты, повышенный возврат инвестиций (ROI) и гораздо более гибкое управление. Однако есть и потенциальные недостатки, или, по крайней мере, проблемы, которые вам необходимо решить, прежде чем выбирать основной сетевой монитор для обработки виртуализированных конечных точек.
В основном это связано с тем, что эти среды гипервизоров, в частности ESXi от VMware и Hyper-V от Microsoft, имеют собственный набор стандартов, которые должны поддерживаться любым инструментом анализа, стремящимся получить из них данные управления. Поставщики должны специально поддерживать возможность обнаружения и мониторинга сред гипервизоров и их виртуальных машин, многие из которых создают свои собственные проблемы. Например, у VMware ESXi есть бесплатный уровень ESXi, который не включает корпоративную среду управления vSphere. Возможность поддерживать ESXi без этого является огромным преимуществом, если вы все равно не используете и его, и vSphere.
Вот почему, помимо тестирования всех основных компонентов мониторинга, мы также рассматриваем каждый из этих инструментов в целом. Какова оптимальная среда мониторинга каждого инструмента и насколько проста каждая система в настройке и использовании? Как правило, определение целей мониторинга зависит от той или иной формы шаблона, доступного для различных типов устройств и сервисных приложений. Некоторые варианты могут включать такие вещи, как HTTP (протокол передачи гипертекста), SSH (Secure Shell), SFTP Secure FTP) или SNMP (простой протокол мониторинга сети). Администраторы заполняют эти шаблоны соответствующей информацией об устройстве или службе, присваивают им имя для рассматриваемой службы, а затем добавляют их в базу данных монитора. Чем меньше кликов мы делаем и полей нужно заполнять, тем лучше результаты нашего тестирования. Если расширенные параметры доступны, но не являются препятствием, это также добавляется к итоговому баллу.
Естественно, помимо мониторинга отдельных устройств и систем, очень важно информировать администраторов о проблемах. Поэтому мы придаем большое значение тому, как каждая система настраивает оповещения. Немедленное знание о серьезной проблеме часто может означать разницу между быстрым решением проблемы и возникновением катастрофы на переднем крае бизнеса. Хотя электронная почта является основным способом работы большинства этих уведомлений, сегодняшнее изобилие онлайн-технологий для совместной работы может предоставить вам гораздо больше возможностей, и все эти инструменты должны поддерживать по крайней мере некоторые из них.
Для нашего тестирования это означает поиск таких вещей, как возможность запускать сторонние приложения для реагирования, инициировать SMS-сообщения и запускать другие онлайн-сервисы, такие как IFTTT (If This Then That). Чем более гибким является общий процесс оповещения, тем лучше мы оцениваем его, потому что это дает клиентам больше вариантов рабочего процесса. Однако эта гибкость должна быть уравновешена простотой использования.
Отчетность — это наш последний критерий, но это критически важный компонент любого приложения для мониторинга сети. Эти инструменты собирают данные, которые ИТ-менеджеры должны использовать немедленно, чтобы поддерживать сети в рабочем состоянии. Таким образом, то, как инструмент представляет эти данные, является ключевым фактором успеха. Кроме того, хотя эти немедленные данные, безусловно, важны, ИТ-администраторам также нужны долгосрочные показатели, чтобы увидеть, как изменения влияют на общую производительность с течением времени.
Другие важные функции для сетевого анализа
Все вышеперечисленное является важными функциями сетевого монитора общего назначения, но есть и другие ключевые функции, даже если они применимы не к каждой сети. Во-первых, с точки зрения администратора, приятно иметь визуальную графику, которая дает вам краткий обзор не только текущего состояния сети, но и визуальную детализацию работоспособности отдельных устройств. Это не то же самое, что отчетность, и некоторые из протестированных нами инструментов явно выделялись в этом отношении. Дополнительным плюсом является возможность настроить расположение графических элементов на панели инструментов.
Управление IP-адресами (IPAM) стало жизненно важной возможностью для многих крупных организаций, и очень важно иметь возможность отслеживать это. Отслеживание статически назначенных адресов, наряду с большим количеством пулов DHCP, не может адекватно управляться с помощью ручной системы. Интеграция IPAM с инструментом управления сетью имеет смысл, поскольку обе функции часто выполняет один и тот же человек.
Автоматизация также является ключом к управлению большим количеством устройств. Чем больше вы можете автоматизировать небольшие административные задачи, тем эффективнее становится процесс. Эту функцию сложно определить количественно, поскольку поставщики обычно подходят к ней по-разному, но автоматические оповещения и ремонт попадают в эту категорию и представляют собой ключевое различие между продуктами.
Наконец, и теперь, когда так много сотрудников (что означает конечные точки для ИТ-специалистов) находятся дома, крайне важной функцией является удаленный доступ. Вы должны иметь возможность удаленного доступа как к инструменту мониторинга сети, так и к конечным точкам и сетям, которыми он управляет.
Как купить подходящий сетевой сканер
Первым шагом для любого ИТ-проекта является определение требований. Выше мы перечислили множество важных возможностей. Но вы можете разбить их на категории, а также искать ключевые базовые возможности, прежде чем рассматривать более продвинутые. Например, вам необходимо просмотреть подробную информацию о ключевых компонентах вашего сетевого оборудования, таких как коммутаторы и маршрутизаторы. Итак, насколько сложно получить к нему доступ и какую именно информацию вы получите?
Во многих организациях нет персонала для круглосуточного наблюдения за экранами компьютеров. Это делает автоматические оповещения, эскалацию и исправление очень важными требованиями для большинства компаний. Но не просто смотрите, существуют ли эти функции, внимательно оцените, как они работают, и убедитесь, что это то, что нужно вашему ИТ-персоналу. Отчеты и мониторинг на основе тенденций помогают определить уровни использования и выявить потенциальные узкие места до того, как они станут проблемой. Еще одним требованием являются хорошие инструменты отчетности, но для многих компаний это также означает возможность создавать настраиваемые отчеты и запросы.
Получив этот список основных требований, вы сможете просмотреть каждый из этих продуктов и определить, соответствуют ли они требованиям. Если более одного продукта соответствует требованиям, вам нужно будет провести самостоятельное тестирование, чтобы увидеть, какой из них лучше всего соответствует вашим потребностям. Вот где важна бесплатная ознакомительная версия, и вы хотите получить к ней доступ как минимум в течение 30 дней.
Наконец, есть цена, хотя для большинства сетевых менеджеров она не является первостепенным критерием при принятии общего решения о покупке. Сопоставьте свои потребности с инструментом, а затем беспокойтесь о цене. Это хороший подход, поскольку цены в этом сегменте различаются, вероятно, потому, что многие претенденты все еще используют модель локального развертывания, которая требует устаревшего локального лицензирования.
Что такое мониторинг сети? | Определение и основы
Основы сетевого мониторинга
Что такое мониторинг сети?
В современном мире термин «мониторинг сети» широко распространен в ИТ-индустрии. Мониторинг сети — это критический ИТ-процесс, при котором все сетевые компоненты, такие как маршрутизаторы, коммутаторы, брандмауэры, серверы и виртуальные машины, отслеживаются на предмет сбоев и производительности и постоянно оцениваются для поддержания и оптимизации их доступности. Одним из важных аспектов сетевого мониторинга является то, что он должен быть упреждающим. Упреждающий поиск проблем с производительностью и узких мест помогает выявить проблемы на начальном этапе. Эффективный упреждающий мониторинг сервера может предотвратить простои или сбои в работе сети.
Важные аспекты мониторинга сети:
- Основы мониторинга
- Оптимизация интервала мониторинга
- Выбор правильного протокола
- Установка порогов
Мониторинг предметов первой необходимости.
Неисправные сетевые устройства влияют на производительность сети. Этого можно избежать путем раннего обнаружения, поэтому мониторинг сетевых устройств имеет первостепенное значение. При эффективном сетевом мониторинге первым шагом является определение устройств и связанных с ними показателей производительности, которые необходимо отслеживать. Второй шаг – определение интервала мониторинга. Такие устройства, как настольные компьютеры и принтеры, не являются критическими и не требуют частого мониторинга, в то время как серверы, маршрутизаторы и коммутаторы выполняют важные для бизнеса задачи, но в то же время имеют определенные параметры, которые можно выборочно отслеживать.
Интервал контроля.
Интервал мониторинга определяет частоту, с которой опрашиваются сетевые устройства и связанные с ними показатели для определения состояния производительности и доступности. Настройка интервалов мониторинга может помочь снять нагрузку с инструментов сетевого мониторинга и отчетности и, в свою очередь, с ваших ресурсов. Интервал зависит от типа сетевого устройства или отслеживаемого параметра. Статус доступности устройств должен контролироваться наименьший интервал времени, желательно каждую минуту. Статистику процессора и памяти можно отслеживать каждые 5 минут. Интервал мониторинга для других показателей, таких как использование диска, может быть увеличен, и его будет достаточно, если он будет опрашиваться каждые 15 минут. Мониторинг каждого устройства с наименьшим интервалом только добавит ненужной нагрузки на сеть и не совсем необходим.
Протокол и его виды.
При мониторинге сети и ее устройств общепринятой практикой является использование безопасного и не потребляющего пропускную способность протокола управления сетью, чтобы свести к минимуму его влияние на производительность сети. Большинство сетевых устройств и серверов Linux поддерживают SNMP (простой протокол управления сетью) и протоколы CLI, а устройства Windows поддерживают протокол WMI. SNMP — это один из широко распространенных сетевых протоколов для управления и мониторинга сетевых элементов. Большинство сетевых элементов поставляются в комплекте с агентом SNMP. Их просто нужно включить и настроить для связи с системой управления сетью (NMS). Разрешение доступа на чтение и запись по протоколу SNMP дает пользователю полный контроль над устройством. С помощью SNMP можно заменить всю конфигурацию устройства. Лучший сетевой монитор помогает администратору управлять сетью, устанавливая привилегии чтения/записи SNMP и ограничивая контроль для других пользователей.
Упреждающий мониторинг и пороговые значения.
Простой сети может стоить больших денег. В большинстве случаев конечный пользователь сообщает о проблеме с сетью группе управления сетью. Причиной этого является плохой подход к проактивному монитору корпоративной сети. Ключевой задачей мониторинга сети в режиме реального времени является упреждающее выявление узких мест в производительности. Именно здесь пороговые значения играют важную роль в приложении мониторинга сети. Пороговые ограничения варьируются от устройства к устройству в зависимости от варианта использования в бизнесе.
Мгновенное оповещение о нарушении порога.
Настройка пороговых значений помогает в упреждающем мониторинге ресурсов и служб, работающих на серверах и сетевых устройствах. Каждое устройство может иметь интервал или пороговое значение, установленное в зависимости от предпочтений и потребностей пользователя. Многоуровневый порог может помочь в классификации и анализе любой обнаруженной неисправности. Используя пороговые значения, оповещения о мониторинге сети могут быть подняты до того, как устройство выйдет из строя или достигнет критического состояния.
Панели управления и персонализация.
Данные становятся полезными только тогда, когда они четко представлены нужной аудитории. Для ИТ-администраторов и пользователей важно знать о критических метриках, как только они входят в систему. Сетевая информационная панель должна предоставлять краткий обзор текущего состояния вашей сети с критическими метриками от маршрутизаторов, коммутаторов, брандмауэров, серверы, службы, приложения, URL-адреса, принтер, ИБП и другие устройства инфраструктуры. Поддержка виджетов для отслеживания требуемой специфики и графиков производительности в реальном времени может помочь администраторам быстро устранять неполадки и удаленно контролировать устройства.
Высокая доступность и отказоустойчивость.
Что происходит, когда ваш доверенный инструмент мониторинга сети работает на сервере, который выходит из строя или теряет сетевое подключение? Вы захотите получить предупреждение об этом, а также автоматически исправить ситуацию, используя резервную / резервную установку другого двойного приложения для мониторинга сети в реальном времени. Высокая доступность относится к постоянной доступности системы мониторинга. О каждом сетевом происшествии — неисправности устройства, недопустимых уровнях пропускной способности, DoS-атаках и т. д. — следует немедленно доводить до вашего сведения, чтобы можно было немедленно принять контрмеры.
Функции аварийного переключения и восстановления после сбоя обеспечивают постоянный мониторинг сетевой среды за счет использования вторичного резервного сервера. Если на первичном сервере происходит сбой, вторичный сервер легко может взять на себя управление, а база данных защищена. Это гарантирует стопроцентную безотказную работу сети и устройств.
Преимущества отказоустойчивой системы:
- Мгновенное распознавание отказа основного сервера.
- Немедленное уведомление по электронной почте в случае отказа основного сервера.
- 100% безотказная работа и бесперебойное управление сетью.
- Автоматическое плавное переключение между основным сервером и резервным сервером и наоборот.
Решения для мониторинга сети.
Процесс сетевого мониторинга и управления упрощается и автоматизируется с помощью программного обеспечения для сетевого мониторинга и инструментов сетевого мониторинга. Из широкого спектра доступных решений для управления сетью важно выбрать систему сетевого мониторинга, которая может эффективно устранять узкие места в сети и проблемы с производительностью, которые могут негативно повлиять на производительность сети. С внезапным всплеском мониторинга корпоративной сети и удаленного мониторинга сети на рынке доступен широкий спектр сетевых мониторов Windows и Linux, а также решений для мониторинга сети. Эффективная система управления сетью будет содержать встроенный инструмент мониторинга сети, который поможет администраторам сократить рабочую силу и автоматизировать основные методы устранения неполадок.
Особенности эффективного программного обеспечения сетевого мониторинга:
- Визуализация всей вашей ИТ-инфраструктуры с дальнейшей классификацией на основе типа или логических групп.
- Автоматическая настройка устройств и интерфейсов по предустановленным шаблонам.
- Мониторинг и устранение неполадок в работе сети, сервера и приложений для обеспечения оптимизации сети.
- Внедрите передовые методы мониторинга производительности сети, чтобы быстро устранять сбои в сети, выявляя корень проблемы.
- Получите расширенные функции отчетности с возможностью планировать и автоматически отправлять по электронной почте или публиковать отчеты.
Мониторинг сети стал важным аспектом управления любой ИТ-инфраструктурой. Точно так же оценка сети считается элементарным шагом в приведении вашей ИТ-инфраструктуры в соответствие с бизнес-целями, что достигается с помощью инструментов мониторинга сети. Узнайте, как оценить свою сеть для выявления угроз безопасности и узких мест в производительности.
Узнайте больше о ManageEngine OpManager — сетевом программном обеспечении, которому доверяют более миллиона сетевых администраторов по всему миру.
Добавить комментарий